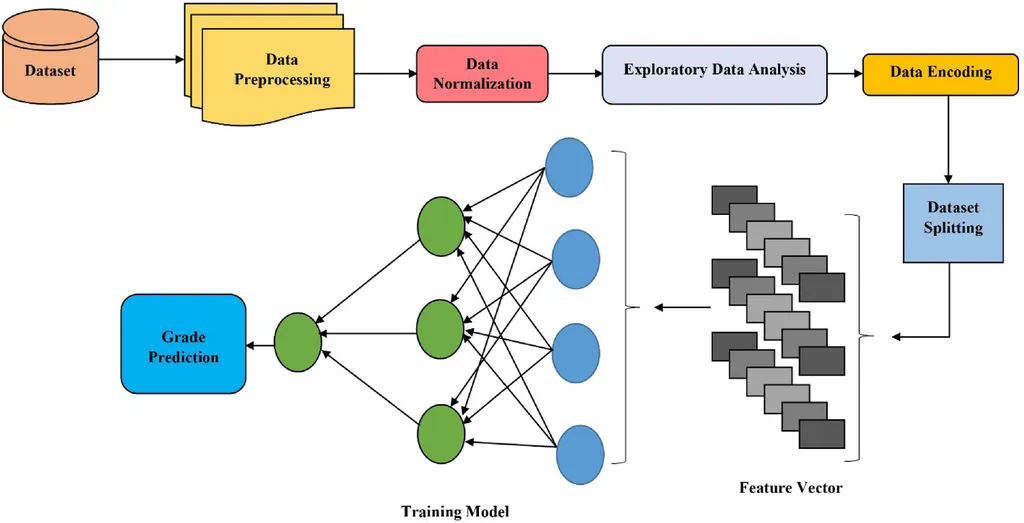
In the fast-paced world of energy technology, where precision and reliability are paramount, a groundbreaking algorithm developed by Ziyuan Zhong and his team at Shenzhen BAK Battery Co., Ltd. is set to revolutionize prediction accuracy. This innovative dynamic classification algorithm, published in the IEEE Access journal, promises to enhance prediction performance in safety-critical domains, with significant implications for the energy sector.
Imagine a world where energy forecasts are not just accurate but flawless, where missed detections are a thing of the past, and false positives are minimized. This is the vision that Zhong and his colleagues at the Intelligent Technology Department in Shenzhen are bringing to life. Their algorithm partitions data in a self-supervised learning-generated way, allowing models to understand data distribution more intuitively. “The key innovation here is the use of self-supervised classification learning,” Zhong explains. “This enables the model to learn from the training set and divide it into subareas, each with its own tailored prediction model.”
The algorithm’s strength lies in its ability to operate within smaller data ranges, refining predictions and filtering out substandard results without the need for additional models. This approach not only improves overall accuracy but also ensures that each model operates within a more manageable data scope, enhancing reliability. “By focusing on small-range subset predictions, we can eliminate inaccurate results and optimize the prediction process,” Zhong adds.
The implications for the energy sector are vast. In an industry where predictive maintenance and accurate forecasting can mean the difference between operational efficiency and costly downtime, this algorithm could be a game-changer. Energy companies often rely on complex models like XGBoost or LGBM to predict equipment failures or optimize energy distribution. However, these models can sometimes fall short in terms of accuracy and reliability. Zhong’s algorithm, with its exceptional performance and minimal false positives, offers a more robust solution.
The algorithm’s potential extends beyond just prediction accuracy. Its ability to refine and filter predictions without additional models means that energy companies can achieve higher reliability with fewer resources. This could lead to significant cost savings and improved operational efficiency. Moreover, the algorithm’s adaptability across multiple datasets suggests that it could be applied to various aspects of the energy sector, from renewable energy forecasting to grid management.
Looking ahead, the future of this algorithm is bright. While there is still room for improvement in automatic parameter tuning and efficiency, the current performance is already outstanding. Future work will focus on optimizing the classification components to enhance robustness and adaptability, making it an even more powerful tool for the energy sector.
As the energy industry continues to evolve, the need for accurate and reliable prediction models becomes ever more critical. Zhong’s dynamic classification algorithm, published in the IEEE Access journal, represents a significant step forward in this direction. By leveraging self-supervised learning and small-range subset predictions, this algorithm promises to shape the future of energy forecasting, making it more precise, reliable, and efficient. As Zhong and his team continue to refine and optimize their algorithm, the energy sector can look forward to a future where prediction accuracy is not just a goal but a reality.