Researchers from the University of Hong Kong, including Chenxu Dang, Jie Wang, Guang Li, Zhiwen Hou, Zihan You, Hangjun Ye, Jie Ma, Long Chen, and Yan Wang, have developed a novel approach to enhance autonomous driving capabilities by integrating vision, language, and action models. Their work, titled “SparseOccVLA: Bridging Occupancy and Vision-Language Models via Sparse Queries for Unified 4D Scene Understanding and Planning,” addresses the challenges of combining high-level reasoning with fine-grained spatial details in autonomous systems.
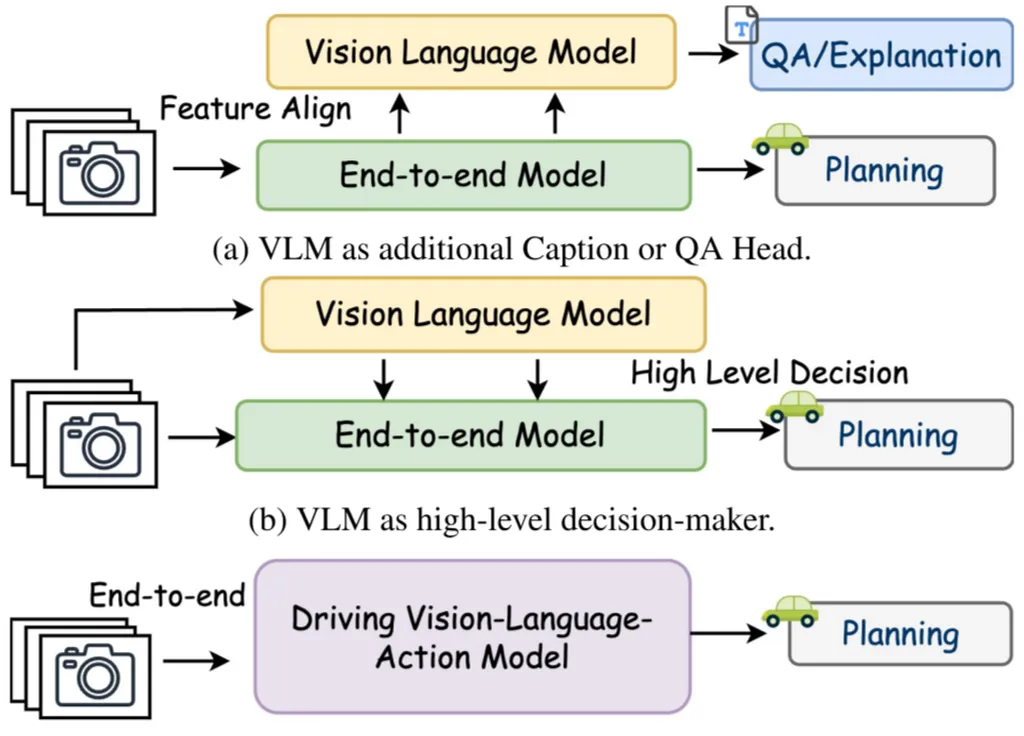
Autonomous vehicles rely on various models to navigate and make decisions. Vision Language Models (VLMs) excel at high-level reasoning tasks, such as understanding and interpreting complex scenes. However, they struggle with detailed spatial reasoning and can suffer from token explosion, where the amount of data becomes unmanageable. On the other hand, semantic occupancy models provide detailed spatial information but are too dense to integrate efficiently with VLMs. The researchers aimed to bridge this gap by developing a unified model that combines the strengths of both approaches.
The team introduced SparseOccVLA, a vision-language-action model that unifies scene understanding, occupancy forecasting, and trajectory planning. The model uses sparse occupancy queries to create a compact yet informative representation of the scene. These queries serve as a bridge between vision and language, allowing the model to reason about the scene and forecast future occupancy. The researchers also developed an LLM-guided Anchor-Diffusion Planner, which features decoupled anchor scoring and denoising, as well as cross-model trajectory-condition fusion. This planner helps the vehicle make informed decisions about its trajectory based on the unified scene understanding.
The results of the study, published in the journal IEEE Transactions on Pattern Analysis and Machine Intelligence, demonstrate significant improvements in various metrics. SparseOccVLA achieved a 7% relative improvement in CIDEr over the state-of-the-art on the OmniDrive-nuScenes dataset, a 0.5 increase in mIoU score on Occ3D-nuScenes, and set a new state-of-the-art open-loop planning metric on the nuScenes benchmark. These improvements highlight the model’s strong holistic capability in integrating vision, language, and action for autonomous driving.
The practical applications of this research for the energy industry are significant. As autonomous vehicles become more prevalent, the demand for efficient and reliable energy sources will increase. By improving the capabilities of autonomous systems, this research can contribute to the development of more energy-efficient transportation solutions. Additionally, the integration of vision, language, and action models can enhance the overall performance of autonomous vehicles, making them safer and more reliable for consumers. This, in turn, can drive the adoption of electric and other alternative fuel vehicles, reducing the overall carbon footprint of the transportation sector.
This article is based on research available at arXiv.