In the realm of energy and technology, the integration of artificial intelligence and machine learning models is becoming increasingly prevalent. Researchers from various institutions, including the University of Technology Sydney, Nanyang Technological University, and the Australian National University, have been exploring ways to enhance the robustness of Vision-Language Models (VLMs), which are crucial for safety-critical applications. Their latest research, titled “MMT-ARD: Multimodal Multi-Teacher Adversarial Robust Distillation for Robust Vision-Language Models,” offers a novel approach to improving the adversarial robustness of these models.
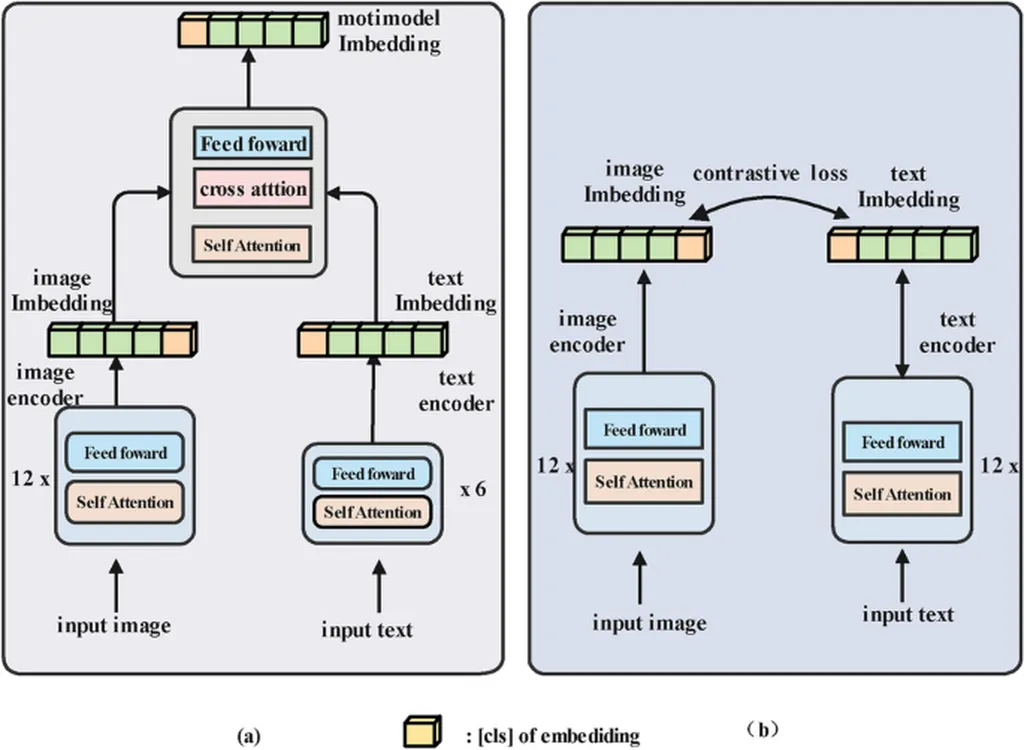
Vision-Language Models (VLMs) are increasingly being deployed in safety-critical applications, making their robustness against adversarial attacks a crucial concern. Traditional methods of transferring robustness from teacher to student models, known as adversarial knowledge distillation, have shown promise but come with limitations. These include limited knowledge diversity, slow convergence, and difficulty in balancing robustness and accuracy.
To address these challenges, the researchers propose a new framework called MMT-ARD, which stands for Multimodal Multi-Teacher Adversarial Robust Distillation. The key innovation of MMT-ARD is its dual-teacher knowledge fusion architecture. This architecture collaboratively optimizes both clean feature preservation and robust feature enhancement, thereby improving the model’s ability to handle adversarial examples.
One of the standout features of MMT-ARD is its dynamic weight allocation strategy. This strategy is based on teacher confidence and enables the model to adaptively focus on harder samples, thereby better handling challenging adversarial examples. Additionally, the researchers introduced an adaptive sigmoid-based weighting function to mitigate bias among teachers, ensuring a balanced strength of knowledge transfer across modalities.
The researchers conducted extensive experiments on ImageNet and zero-shot benchmarks. They found that MMT-ARD improves robust accuracy by 4.32% and zero-shot accuracy by 3.5% on the ViT-B-32 model. Furthermore, MMT-ARD achieves a 2.3x increase in training efficiency over traditional single-teacher methods. These results highlight the effectiveness and scalability of MMT-ARD in enhancing the adversarial robustness of multimodal large models.
In the energy sector, robust Vision-Language Models can be applied to various safety-critical applications, such as monitoring and maintaining energy infrastructure. For instance, these models can be used to analyze images and videos from drones or satellites to detect anomalies in power lines, pipelines, or solar panels. The improved robustness against adversarial attacks ensures that these models can operate reliably in real-world, often unpredictable environments.
The research was published in the prestigious journal, arXiv, which is known for its rigorous peer-review process and high standards of scientific excellence. The code for MMT-ARD is available on GitHub, making it accessible for other researchers and practitioners to build upon and apply in their own work. This open-access approach fosters collaboration and accelerates the development of robust AI models for the energy sector and beyond.
This article is based on research available at arXiv.